Redis简单介绍与使用
文章目录
什么是NoSQL -> Not Only SQL
k-v模式存储
- 不遵循SQL标准
- 不支持ACID(不代表不支持事务)
- 远超于SQL的性能
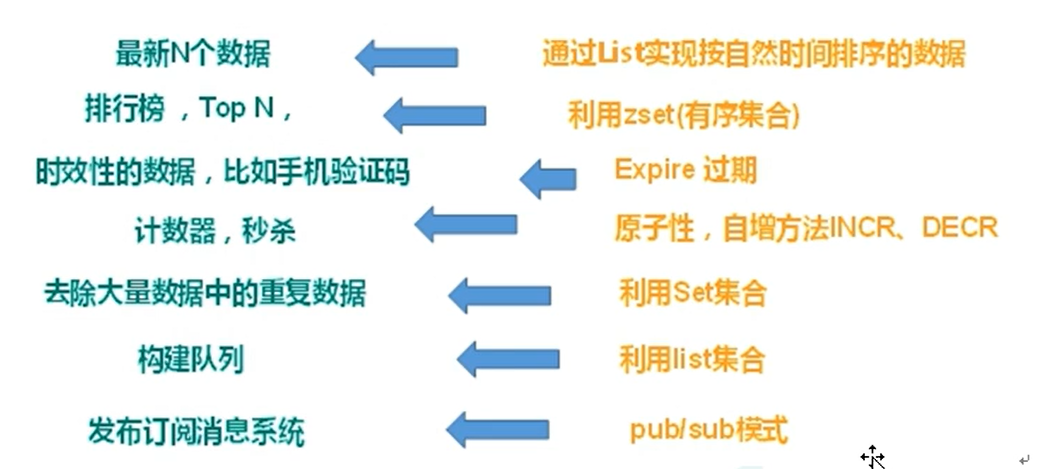
适用场景
- 对数据高并发的读写
- 海量数据的读写
- 对数据高可扩展性的
不适合场景
- 需要事务支持
- 基于sql的结构化查询存储,处理复杂的关系,需要及时查询
- 用不着sql,或者用了sql也不行的时候,可以考虑使用NoSQL
和其他的NoSQL对比
Memcache
- 不支持持久化
- k-v模式,但是支持类型单一
- 一般作为缓存数据库,辅助持久化的数据库
Redis
- 支持持久化,主要用作备份恢复
- 支持多种数据结构的存储,比如list,set,hash,zset
- 一般作为缓存数据库,辅助持久化的数据库
MongoDB
- 高性能,开源,模式自由(schema free)的文档型数据库
- 数据都在内存中
行式数据库 列式数据库
图关系型数据库(社会关系,公共交通网络,拓扑图)
安装和概述
不过多介绍了.
值得提的一点,Redis的操作都是原子性的(线程安全的)
用途
Redis 各目录说明
- redis-benchmark: 性能测试工具,可以在自己本子运行,看看自己本子性能如何
- redis-check-aof: 修复有问题的AOF文件,rdb
- redis-server 服务器启动命令(前台启动,不推荐)
- redis-cli: 客户端,操作入口
后台启动
redis.conf 配置文件 将daemonize: no 改成 yes redis-server redis.conf (后台启动)
常用命令
- dbsize 查看key的数量
- flushdb 清除当前库
- flushall 清除所有
ps -ef | grep redis 查找redis的进程 redis 是单线程 + 多路Io复用 多路复用: memcache 多线程 + 锁
常用五大数据类型
3.1 Redis 键(key)
- key * 查看当前库的所有key
- del key 删除key
- set key val 设置key
- exists key 判断key是否存在 返回值是int
- type key 查看key的类型
- del k3 删除指定的key
- unlink key 仅将keys从 keyspaes 删除,真正的删除
- ttl key 查看什么时候过期, (-1 永不过期,-2 已经过期)
- expire key 10 设置key 10s过期
- select 命令 切换数据库
3.2 Redis 字符串(string)
一个Redis 中字符串value最多是 512m 二进制安全的
- get key 取值
- append key value 追加
- strlen key 获得值的长度
- setnx k1 v1 只有key不存在的时候,才会设置key的值
针对数字操作的命令
-
incr key 将key中存储的数字+1
-
decr key 将key中存储的数字-1
-
incrby key <步长>
-
decrby key <步长>
原子操作:
-
指不会被线程调度机制打断的操作
-
在单线程中,能够在单条指令中完成的操作都可以认为是“原子操作”,因为中断只能发生于指令之间
-
在多线程中,不能被其他进程(线程)打断的操作就叫原子操作 Redis 单命令的原子性主要得益于Redis的单线程
-
mset k1 v1 k2 v2 设置多个 k-value
-
mget k1 v1 k2 v2 获取多个 k-value
-
msetnx 类似上同 且原子性,只要有一个key 不存在,全部设置失败,否则才成功
-
getrange key <起始位置><终止位置> 都是闭区间
-
set range key
-
setex key <过期时间> value
-
getset key newvalue 获取并设置新值
String的数据结构为简单动态字符串(Simple Dynamic String,缩写SDS)。是可以修改的字符串,内部结构实现类似于java的ArrayList,采用预分配冗余空间的方式(扩容机制)来减少内存的频繁分配。
扩容机制 *2 超过1m之后每次加1m
Redis 列表(List)
- 单键多值
- 类似双向链表(java的Linkedlist),对两端操作性能很高,但是通过索引下标的操作中间的节点性能很差(需要遍历,毕竟不是顺序存储)
常用命令
- lpush/rpush k1 v1 v2 v3 … 从左边/右边插入多个值(以左边放的方式就是头插法,v3,v2, v1, 右边就是尾插法)
- lpop/rpop 上同
- lrange k1 0 -1 取出所有
- rpoplpush
从 列表右边吐出来一个值插入到 列表的左边 没有lpoprpush 的命令 - lindex key
按照索引下标获得元素 - llen
获得列表长度 - linsert
before 在value的后面插入newvalue - lrem
从左边删除n个value(从左到右) - lset
将列表key 下标为index的值替换成value
数据结构
List 的数据结构为快速链表(quicklist) 首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也就是压缩列表。 它将所有的元素紧挨着一起存储(顺序存储),分配一块连续的内存。 当数据量比较多的时候才会转成quicklist 因为普通链表需要的附加指针空间太大,比较浪费空间。比如这个列表里只是int类型的数据,结构上还需要两个额外的指针prev和next。 ziplist <-> ziplist <-> ziplist <-> ziplist <-> ziplist 上面这样就变成了quicklist Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针穿起来使用。这样既满足了快速插入删除的性能,又不会出现太大的空间冗余。 (设计的真牛皮)
Redis 集合(set)
类似list,但是可以自动去重 Redis 的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)
常用命令
- sadd
… 将一个或者多个member元素加入到集合key中,已经存在的member元素将被忽略 - smembers
取出该集合的所有值 - simember
判断集合 中是否有 值,有返回1,否则返回0 - scard
返回集合的元素个数 - srem
删除集合中的这些元素 - spop
随机从集合中吐出一个值(因为无序)(吐出,也代表删除了) - srandmember
随机的从该集合取出n个值。不会从集合中删除 - smove
value 把集合中一个值移动到另一个集合 - sinter
返回两个集合的交集 - snuion
返回两个集合的并集 - sdiff
返回两个集合的差集
底层数据结构
Set 数据结构是dict字典,字典是用哈希表实现的 Java中Hashset的内部实现使用的是HashMap,只不过所有的value都指向同一个都西昂。Redis的set结构也是一样,它的内部也是用hash结构,所有的value都指向同一个内部值。
Redis 哈希(Hash)
Redis hash 是一个键值对集合,是一个string类型的field 和 value 的映射表,hash特别适合用于存储对象。 类似java里面的map<String.Object>
常用命令
- hset
给 集合中的 键赋值 value(这种数据结构就是set 里面套一个map) - hget
从 集合 取出value - hmset
批量设置hash的值 - hexists
查看哈希表key中,给定域field是否存在 - hkeys
列出该hash集合的所有field - hvals
列出该hash集合的所有value - hincrby
为哈希表key中的域field的值几上增量1 , -1 - hsetnx
将哈希表key中的域field的值设置为value,当且仅当域field不存在时
数据结构
Hash 类型对应的数据结构是两种:ziplist,hashtable 当field-value 长度较短且个数较少时,使用ziplist,否则是哦那个hashtbale
Redis 有序集合 Zset
与set的区别是:
- 有序
- 有序集合的每个成员都关联了一个评分(score),这个频分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以重复。
- 因为有序,所以可以根据评分或者次序很快的获取到一个特定范围的元素
- 访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复元素的智能列表
常用命令
- zadd
将一个或者多个member及其score值加入到有序集合key中 - zrange
[WITHSCORES](可以带上分数) 返回有序集合key中,下标在start-stop之间的元素,带上withscores ,分数一起和值返回到结果集 - zrangebyscore key minmax[withscores][limit offset count] 返回有序集合key中,所有score值介于min 和 max之间(包括等于min或max)的成员。有序集成员按score值递增(从小到大)次序排列。
- zrevranegebyscore key maxmin [withscores][limit offset count] 同上,改为从大到小排序
- zincrby
为元素的score加上增量 - zrem
删除该集合下指定值的元素 - zcount
统计该集合,分数区间内的元素个数 - zrank
返回该值在集合中的排名,从0开始
案例:如何利用zset实现一个文章访问排行榜
数据结构
SortedSet(zset) 是Redis提供的一个非常特别的数据结构,一方面它等价于java的数据结构Map<String, Double>, 可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名词,还可以通过score的范围来获取元素的列表。
zset 底层使用了两个数据结构 (1)hash, hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。 (2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表
跳跃表(跳表)
发布和订阅
什么是发布和订阅
Redis发布订阅(Pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接受消息 Redis客户端可以订阅任意数量的频道
发布订阅的实现
- subscribe channel1 订阅频道1
- publish channel1 hello 向频道1发布信息
Redis最新版本的新的数据类型
Bitmaps
Redis 提供了Bitmaps这个“数据类型”可以实现对位的操作。:
- Bitmaps 本身不是一种数据类型,实际上它就是字符串(key- value),但是它可以对字符串进行的位进行操作
- Bitmaps 单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。可以把Bitmaps想象成一个以位为单位的数组,数组的每个单元只能存储0和1,数组的下标在Bitmaps中叫做偏移量。
常用命令
- setbit
- getbit
- bitcount
HyperLogLog
Geospatial
Redis事务
Redis事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序的执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断 Redis事务的主要作用就是串联多个命令防止别的命令插队
Multi、Exec、discard
当输入 Multi命令开始,输入的命令就会一次进入命令队列中,但不会执行,知道输入Exec,redis将之前的命令队列中的命令一次执行。 组队过程中可以通过discard放弃某个命令
事务的错误处理
组队过程中
- 组队过程中有任何一个命令出错,所有命令都不会执行 执行过程中
- 执行过程中,如果有命令报错,只有该命令执行失败
事务的冲突问题
例子
一个请求想给金额 - 8000 一个请求想给金额 - 5000 一个请求想给金额 - 1000 账户金额 10000
|
|
悲观锁
每次在操作的时候,都认为别人会去修改,所以在每次拿数据的时候都会上锁。这样别人想拿这个数据就会阻塞到这个人拿到锁。 例如MySQL的行锁,表锁,读锁,写锁等。 都是操作之前先上锁,效率低。
乐观锁
加上一个版本号, 版本号同步更新 版本号不一致就不能操作。(判断读的版本号和要操作数据的版本号是否一致) 乐观锁适合多读的应用类型,可以提高吞吐量。 Redis就是利用这种check-and-set机制实现事务的。
WATCH key [key…]
在执行multi 之前,先执行watch key1[key2] 可以监视一个或者多个key,如果事务执行之前这个key被其他命令所改动,那么事务将被打断。(乐观锁)
- unwatch 取消监视
持久化
RDB 写到磁盘
在制定的时间间隔类内将内存中的数据集快照写入磁盘,也就是Snapshot快照,它恢复时是将快照文件直接读到内存里。
备份是如何实现的
AOF 追加
文章作者 bing
上次更新 2020-05-12