python网络采集读书笔记
第一章
1
2
|
import urllib
html = ulropen("http://www.pythonscraping.com/page/page1.html")
|
网页是十分复杂的,网页数据格式更是如此。
所以让我们来看看import 之后的这行代码可能会发生的异常:
第一种异常发生时,程序会返回HTTP错误。HTTP错误可能是"404 Page Not Found"“500
Internal Server Error"等。所有类似情形,urlopen 函数都会抛出"HTTP Error”异常。我们可以用下面的方式处理这种异常:
1
2
3
4
5
6
7
8
|
try:
html = urlopen("http://www.pythonscraping.com/pages/page1.html")
except HTTPError as e:
print(e)
# 返回空值,中断程序,或者执行另一个方案
else:
# 程序继续。注意:如果你已经在上面异常捕捉那一段代码里返回或中断(break),
# 那么就不需要使用else语句了,这段代码也不会执行
|
如果程序返回 HTTP 错误代码,程序就会显示错误内容,不再执行 else 语句后面的代码。
如果服务器不存在(就是说链接 http://www.pythonscraping.com/ 打不开,或者是 URL 链接写错了),urlopen 会返回一个 None 对象。这个对象与其他编程语言中的 null 类似。我们可以增加一个判断语句检测返回的 html是不是 None:
1
2
3
4
|
if html is None:
print("URL is not found")
else:
# 程序继续
|
而且网页已经从服务器获取,网页内从并非完全是我们期望的那样,仍然可能会出现异常。
例如,如果从Beautiful soup 对象中取一个不存在的对象,会返回None,
如果对该不存在的标签继续取它的子标签就会产生AttributeError错误。
所以厝里和检查这个对象是十分必要的
对两种状况进行检查
1
2
3
4
5
6
7
8
9
10
|
# nonExistingTag 代表一个不存在的标签
try:
badContent = bsObj.nonExistingTag.anotherTag
except AttributeError as e:
print("Tag was not found")
else:
if badContent == None:
print ("Tag was not found")
else:
print(badContent)
|
重新对整个过程组织一下代码,让她(没错,情人)变得不那么难看(难读)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def getTitle(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read())
title = bsObj.body.h1
except AttributeError as e:
return None
return title
title = getTitle("http://www.pythonscraping.com/pages/page1.html")
if title == None:
print("Title could not be found")
else:
print(title)
|
第二章
BeautifulSoup初识
1
2
3
4
5
6
7
8
9
|
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/warandpeace.html")
bsObj = BeautifulSoup(html.read())
# 选择span标签,class属性-值为green
# 返回结果是列表形式
namelist = bsObj.findAll("span",{"class":"green"})
for name in namelist:
print(name.get_text)
|
什么时候使用get_ext()与什么时候应该保留标签
.get_text() 会把你正在处理的 HTML 文档中所有的标签都清除,然后返回一个只包含文字的字符串。假如你正在处理一个包含许多超链接、段落和标签的大段源代码,那么 .get_text() 会把这些超链接、段落和标签都清除掉,只剩下一串不带标签的文字。
用 BeautifulSoup 对象查找你想要的信息,比直接在 HTML 文本里查找信息要简单得多。通常在你准备打印、存储和操作数据时,应该最后才使用 .get_text()。一般情况下,你应该尽可能地保留 HTML 文档的标签结构。
2.2.1 BeautifulSoup的**find()**和`findAll()
参数:
-
tag – 多个参数以集合形式传递{“1”,“2”}1,2为标签名
-
attributes – 以python 中字典的形式传递
-
recursive – 递归 – 递归参数 recursive 是一个布尔变量
- recursive
设置为True,findAll就会根据你的要求去查找标签参数的所有子标签,以及子标签的子标签。如果recursive设置为False,findAll 就只查找文档的一级标签。findAll 默认是支持递归查找的(recursive默认值是True`);一般情况下这个参数不需要设置,除非你真正了解自己需要哪些信息,而且抓取速度非常重要,那时你可以设置递归参数。
-
text – 使用标签内的文本内容进行匹配
-
limit – find 函数相当于 findAll 函数将limit=1
-
keywords – 可以让你选择那些具有指定属性的标签
但是建议不要使用keyword参数,完全可以被其他技术代替,是Beautiful在技术上做的一个冗余功能。
例如,下面两行代码是完全一样的。
1
2
|
bsObj.findAll(id="text")
bsObj.findAll("", {"id":"text"})
|
- 另外,用
keyword 偶尔会出现问题,尤其是在用 class 属性查找标签的时候,因为 class 是 Python 中受保护的关键字。也就是说,class 是 Python 语言的保留字,在 Python 程序里是不能当作变量或参数名使用的(和前面介绍的 BeautifulSoup.findAll() 里的 keyword无关)2。假如你运行下面的代码,Python 就会因为你误用 class 保留字而产生一个语法错误:
1
|
bsObj.findAll(class="green")
|
不过,你可以用 BeautifulSoup 提供的有点儿臃肿的方案,在 class 后面增加一个下划线:
1
|
bsObj.findAll(class_="green")
|
另外,你也可以用属性参数把 class 用引号包起来:
1
|
bsObj.findAll("", {"class":"green"})
|
2.2.2 其他BeautifulSoup对象
看到这里,你已经见过 BeautifulSoup 库里的两种对象了。
前面代码示例中的 bsObj
BeautifulSoup 对象通过 find 和 findAll,或者直接调用子标签获取的一列对象或单个对象,就像:
下面的这两者虽然不常用,可以了解一下。
用来表示标签里的文字,不是标签(有些函数可以操作和生成 NavigableString 对象,而不是标签对象)。
用来查找 HTML 文档的注释标签,用来查找 HTML 文档的注释标签,
2.2.3 导航树
1. 处理子标签和后代标签
一般情况下,BeautifulSoup 函数总是处理当前标签的后代标签。例如,bsObj.body.h1 选择了 body 标签后代里的第一个 h1 标签,不会去找 body 外面的标签。
如果只是想找出子标签,可以用.children标签:
1
2
3
4
5
6
7
8
|
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
for child in bsObj.find("table", {"id":"giftList"}).children:
print(child)
|
一般情况下,BeautifulSoup 函数总是处理当前标签的后代标签。例如,bsObj.body.h1 选择了 body 标签后代里的第一个 h1 标签,不会去找 body 外面的标签。
2. 处理兄弟标签
BeautifulSoup 的 next_siblings() 函数可以让收集表格数据成为简单的事情,尤其是处理带标题行的表格:
让标签的选择更具体
即使页面上只有一个表格(或其他目标标签),只用标签也很容易丢失细节。另外,页面布局总是不断变化的。一个标签这次是在表格中第一行的位置,没准儿哪天就在第二行或第三行了。如果想让你的爬虫更稳定,最好还是让标签的选择更加具体。如果有属性,就利用标签的属性。
同样有next_sibling 函数就有previous_sibling函数、以及next_siblings、previous_siblings函数
3. 父标签处理
.parents – 父标签查找函数
2.3 正则表达式
计算机科学里曾经有个笑话:“如果你有一个问题打算用正则表达式(regular expression)来解决,那么就是两个问题了。”
| 符号 | 含义 | 例子 | 匹配结果 |
| :–: | :———————————————–: | :——: | :————————-: |
| * | 匹配前面的字符、子表达式或括号里的字符 0 次或多次 | a*b* | aaaaaaaa,aaabbbbb,bbbbbb |
| + | 匹配前面的字符、子表达式或括号里的字符至少 1 次 | a+b+ | aaaaaaab,aaabbbbb,abbbbbb |
| [] | 匹配任意一个字符(相当于“任选一个”) | [A-Z]* | APPLE,CAPITALS, |
| [] | 匹配任意一个字符(相当于“任选一个”) | [A-Z]* | APPLE,CAPITALS,QWERTY |
| ——- | ———————————————————— | —————– | —————————— |
| () | 表达式编组(在正则表达式的规则里编组会优先运行) | (a*b)* | aaabaab,abaaab,ababaaaaab |
| {m,n} | 匹配前面的字符、子表达式或括号里的字符 m 到 n 次(包含 m 或 n) | a{2,3}b{2,3} | aabbb,aaabbb,aabb |
| [^] | 匹配任意一个不在中括号里的字符 | [^A-Z]* | apple,lowercase,qwerty |
| | | 匹配任意一个由竖线分割的字符、子表达式(注意是竖线,不是大字字母I) | b(a|i|e)d | bad,bid,bed |
| . | 匹配任意单个字符(包括符号、数字和空格等) | b.d | bad,bzd,b$d,b d |
| ^ | 指字符串开始位置的字符或子表达式 | ^a | apple,asdf,a |
| \ | 转义字符(把有特殊含义的字符转换成字面形式) | \.\ | \\ | . | \ |
| $ | 经常用在正则表达式的末尾,表示“从字符串的末端匹配”。如果不用它,每个正则表达式实际都带着“.*”模式,只会从字符串开头进行匹配。这个符号可以看成是 ^ 符号的反义词 | [A-Z]*[a-z]*$ | ABCabc,zzzyx,Bob |
| ?! | “不包含”。这个奇怪的组合通常放在字符或正则表达式前面,表示字符不能出现在目标字符串里。这个符号比较难用,字符通常会在字符串的不同部位出现。如果要在整个字符串中全部排除某个字符,就加上 ^ 和 $符号 |
`^((?
![A-Z]).)*$` | no-caps-here,$ymb0ls a4e f!ne |
2.4 正则表达式和BeautifulSoup
一般来说,大多数支持支持字符串参数的函数(比如,find(id = “aTagIdHere”))都可以用正则表达式实现。
2.5 获取属性
到目前为止,我们已经介绍过如何获取和过滤标签,以及获取标签里的内容。但是,在网络数据采集时你经常不需要查找标签的内容,而是需要查找标签属性。比如标签 指向的 URL 链接包含在 href 属性中,或者 标签的图片文件包含在 src 属性中,这时获取标签属性就变得非常有用了。
对于一个标签对象,可以用下面的代码获取它的全部属性:
要注意这行代码返回的是一个 Python 字典对象,可以获取和操作这些属性。比如要获取图片的资源位置 src,可以用下面这行代码:
2.6 Lambda表达式
Lambda 表达式本质上就是一个函数,可以作为其他函数的变量使用;也就是说,一个函数不是定义成 f(x, y),而是定义成 f(g(x), y),或 f(g(x), h(x)) 的形式。
BeautifulSoup 允许我们把特定函数类型当作 findAll 函数的参数。唯一的限制条件是这些函数必须把一个标签作为参数且返回结果是布尔类型。
BeautifulSoup 用这个函数来评估它遇到的每个标签对象,最后把评估结果为“真”的标签保留,把其他标签剔除。
例如,下面的代码就是获取有两个属性的标签:
1
|
soup.findAll(lambda tag: len(tag.attrs) == 2)
|
这行代码会找出下面的标签:
1
2
|
<div class="body" id="content"></div>
<span style="color:red" class="title"></span>
|
第 3 章 开始采集
3.1 遍历单个域名
“维基百科六度分隔理论”
用该理论来爬取维基百科的词条。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
from bs4 import BeautifulSoup
from urllib.request import urlopen
import re
import datetime
import random
# 创建随机数"种子"(random seed)
# 完全相同的种子每次均会产生相同的"随机"数序列
random.seed(datetime.datetime.now())
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
return bsObj.find("div", {"id":"bodyContent"}).findAll("a",
href=re.compile("^(/wiki/)((?!:).)*$"))
links = getLinks("/wiki/Kevin_Bacon")
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs["href"]
print(newArticle)
links = getLinks(newArticle)
|
上面的random为 Python 的伪随机数(pseudorandom number)生成器用的是梅森旋转(Mersenne Twister)算法,比较耗费CPU资源。
3.2 采集整个网站
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
pages = set()
def getLinks(pageUrl):
global pages
html = urlopen("http://en.wikipedia.org"+pageUrl)
bsObj = BeautifulSoup(html)
for link in bsObj.findAll("a", href=re.compile("^(/wiki/)")):
if 'href' in link.attrs:
if link.attrs['href'] not in pages:
# 我们遇到了新页面
newPage = link.attrs['href']
print(newPage)
pages.add(newPage)
getLinks(newPage)
getLinks("")
|
关于递归的警告Python 默认的递归限制(程序递归地自我调用次数)是 1000 次。
3.3 通过互联网采集
在你写爬虫随意跟随外链跳转之前,请问自己几个问题。
-
我要收集哪些数据?这些数据可以通过采集几个已经确定的网站(永远是最简单的做法)完成吗?或者我的爬虫需要发现那些我可能不知道的网站吗?
-
当我的爬虫到了某个网站,它是立即顺着下一个出站链接跳到一个新网站,还是在网站上呆一会儿,深入采集网站的内容?
-
有没有我不想采集的一类网站?我对非英文网站的内容感兴趣吗?
-
如果我的网络爬虫引起了某个网站网管的怀疑,我如何避免法律责任?(关于这个问题的更多信息请参考附录 C。)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
from urllib.request import urlopen
from urllib.parse import urlparse
from bs4 import BeautifulSoup
import re
import datetime
import random
pages = set()
random.seed(datetime.datetime.now())
# 获取页面所有内链的列表
def getInternalLinks(bsObj, includeUrl):
#这句代码的意思是获得(includeUrl)的协议 -- 例如:http/htpps
includeUrl = urlparse(includeUrl).scheme+"://"+urlparse(includeUrl).netloc
#推测出该.netloc 是取(includeUrl)的域名 例如:www.baidu.com/www.wiki.com
internalLinks = []
# 找出所有以"/"开头的链接
for link in bsObj.findAll("a", href=re.compile("^(/|.*"+includeUrl+")")):
if link.attrs['href'] is not None:
if link.attrs['href'] not in internalLinks:
internalLinks.append(link.attrs['href'])
else:
internalLinks.append(link.attrs['href'])
return internalLinks
# 获取页面所有外链的列表
def getExternalLinks(bsObj, excludeUrl):
externalLinks = []
# 找出所有以"http"或"www"开头且不包含当前URL的链接
for link in bsObj.findAll("a",href=re.compile("^(http|www)((?!"+excludeUrl+").)*$")):
if link.attrs['href'] is not None:
if link.attrs['href'] not in externalLinks:
externalLinks.append(link.attrs['href'])
return externalLinks
# 爬去地址
def splitAddress(address):
addressParts = address.replace("http://", "").split("/")
return addressParts
# 获取随机外链接
def getRandomExternalLink(startingPage):
html = urlopen(startingPage)
bsObj = BeautifulSoup(html)
# [0]--返回一个列表,获取外链
externalLinks = getExternalLinks(bsObj, splitAddress(startingPage)[0])
if len(externalLinks) == 0:
print("No external links, looking around the site for one")
domain = urlparse(startingPage).scheme+"://"+urlparse(startingPage).netloc
internalLinks = getInternalLinks(bsObj, domain)
internalLinks = getInternalLinks(startingPage)
return getNextExternalLink(internalLinks[random.randint(0,
len(internalLinks)-1)])
else:
return externalLinks[random.randint(0, len(externalLinks)-1)]
def followExternalOnly(startingSite):
externalLink = getRandomExternalLink(startingSite)
print("Random external link is: "+externalLink)
followExternalOnly(externalLink)
followExternalOnly("http://oreilly.com")
|
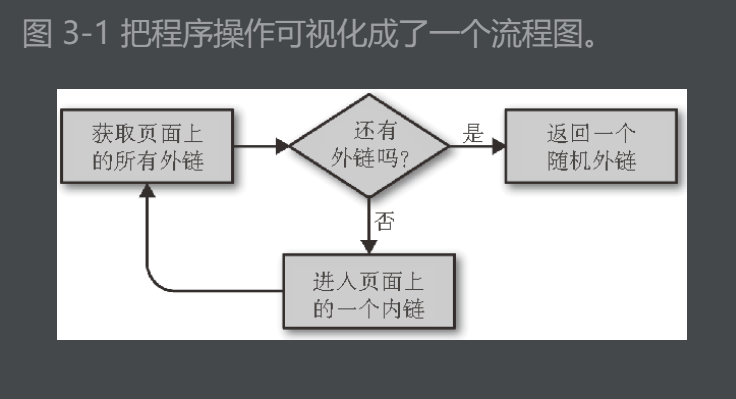
不要把示例程序放进产品代码
如果爬虫遇到一个网站里面一个外链都没有(虽然不太可能,但是如果程序运行的时候够长总会遇到这类情况),这时程序就会一直在这个网站运行跳不出去,直到递归到达 Python 的限制为止。
总结:真实产品代码中必须有的检查和异常处理。
把任务分解成像“获取页面上所有外链”这样的小函数是不错的做法,以后可以方便地修改代码以满足另一个采集任务的需求。例如,如果我们的目标是采集一个网站所有的外链,并且记录每一个外链,我们可以增加下面的函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# 收集网站上发现的所有外链列表
# 用集合存储外链和内链
allExtLinks = set()
allIntLinks = set()
def getAllExternalLinks(siteUrl):
html = urlopen(siteUrl)
bsOvj = BeautifulSoup(html)
internalLinks = getAllExternalLinks(bsObj,splitAddress(siteUrl)[0])
externalLinks = getAllExternalLinks(bsObj,splitAddress(siteUrl)[0])
for link in externalLinks:
if link not in allExtLinks:
allExtLinks.add(link)
print(link)
for link in internalLinks:
if link not in allIntLinks:
print("即将获取链接的URL是:"+link)
allIntLinks.add(link)
getAllExternalLinks(link)
getAllExternalLinks("http://oreilly.com")
|
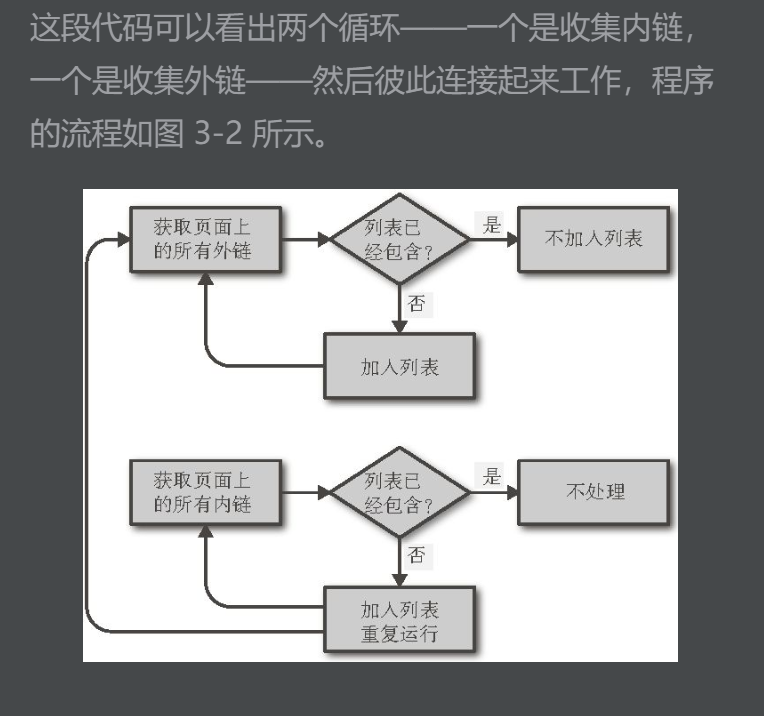
3.4 用Scrapy采集
写网络爬虫的挑战之一是你经常需要不断地重复一些简单任务:找出页面上的所有链接,区分内链与外链,跳转到新的页面。
Scrapy 就是一个帮你大幅度降低网页链接查找和识别工作复杂度的 Python 库
在当前目录下创建一个Scrapy项目(这和Django一样)
1
|
scrapy startproject wikiSpider
|
wikiSpider是新项目的名称。在当前目录中会新建一个名称也是wikiSpider的项目文件夹。文件夹的目录结构如下所示:

Scrapy的每个Item(条目)对象表示网站上的一个页面。
4、 API
和爬虫类似,都是像服务器发送HTTP请求,获得数据。
不同的是,API是将预先打包好的数据(明显更有价值)发送给请求者。 并且 返回的格式类型为XML、或者JSON(更推荐)
存储数据
如果你准备创建一个网站的后端服务或者创建自己的 API,那么可能都需要让爬虫把数据写入数据库。如果你需要一个快速简单的方法收集网上的文档,然后存到你的硬盘里,那么可能需要创建一个文件流(file stream)来实现。如果还要为偶然事件提个醒儿,或者每天定时收集当天累计的数据,就给自己发一封邮件吧!
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def getAbsoluteURL(baseUrl, source):
if source.startswith("http://www."):
url = "http://"+source[11:]
elif source.startswith("http://"):
url = source
elif source.startswith("www."):
url = "http://"+source[4:]
else:
url = baseUrl+"/"+source
if baseUrl not in url:
return None
return url
# 这个函数的功能就是调整url的正确性
|
5.2 把数据存储到CSV文件中
1
2
3
4
5
6
7
8
9
|
import csv
csvFile = open("../files/test.csv", 'w+')
try:
writer = csv.writer(csvFile)
writer.writerow(('number', 'number plus 2', 'number times 2'))
for i in range(10):
writer.writerow( (i, i+2, i*2))
finally:
csvFile.close()
|
运行完成后
1
2
3
4
5
|
number,number plus 2,number times 2
0,2,0
1,3,2
2,4,4
...
|
网络数据采集的一个常用功能就是获取 HTML 表格并写入 CSV 文件。维基百科的文本编辑器对比词条(https://en.wikipedia.org/wiki/Comparison_of_text_editors)中用了许多复杂的 HTML 表格,用到了颜色、链接、排序,以及其他在写入 CSV 文件之前需要忽略的 HTML 元素。用 BeautifulSoup 和 get_text() 函数,你可以用十几行代码完成这件事:
5.3、 MySQL
关系型数据库?
关系型数据时,他们指的是那些并非孤立的数据——它们的属性与其他的数据是有关联的。
5.3.1、 安装MySQL
归根到底,MySQL 就是由一系列数据文件构成的,储存在你的远端服务器或本地的电脑上,里面包含了数据库存储的所有信息。MySQL 软件层提供了一种与数据交互的便捷操作方法。
5.3.2、 基本命令
创建数据库
1
|
>CREATE DATABASE scraping;
|
使用某个数据库(需要制定名称)
1
2
|
>USE scraping;
使用的上个命令的数据库
|
创建一个储存采集的网页的表
结果会显示错误
和其他数据库不同,MySQL数据表必须至少有一列,否则不能创建
为了在 MySQL 里定义字段(数据列),你必须在 CREATE TABLE 语句后面,把字段的定义放进一个带括号的、内部由逗号分隔的列表中:
1
2
3
|
>CREATE TABLE pages (id BIGINT(7) NOT NULL AUTO_INCREMENT, title VARCHAR(200),
content VARCHAR(10000), created TIMESTAMP DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY
(id));
|
每个字段定义由三部分组成:
在字段定义列表的最后,还要定义一个“主键”(key)。MySQL 用这个主键来组织表的内容,便于后面快速查询。
语句执行之后,你可以用 DESCRIBE 查看数据表的结构:
1
2
3
4
5
6
7
8
9
10
|
> DESCRIBE pages;
+---------+----------------+------+-----+-------------------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------+----------------+------+-----+-------------------+----------------+
| id | bigint(7) | NO | PRI | NULL | auto_increment |
| title | varchar(200) | YES | | NULL | |
| content | varchar(10000) | YES | | NULL | |
| created | timestamp | NO | | CURRENT_TIMESTAMP | |
+---------+----------------+------+-----+-------------------+----------------+
4 rows in set (0.00 sec)
|
插入命令
1
2
|
> INSERT INTO pages (title, content) VALUES ("Test page title", "This is some te
st page content. It can be up to 10,000 characters long.");
|
请不要在表中插入数据中带有id字段,这样很不好。让MySQL自己处理ID和timetamp字段
选择命令
1
|
>SELECT * FROM pages WHERE id = 2;
|
下面这个不区分大小写的查询,会返回 title 字段里包含“test”的所有行(% 符号表示 MySQL 字符串通配符)的所有字段:
1
|
>SELECT * FROM pages WHERE title LIKE "%test%";
|
如果你的表有很多字段,而你只想返回部分字段怎么办?
1
|
>SELECT id, title FROM pages WHERE content LIKE "%page content%";
|
这样就只会返回 title 字段包含“page content”的所有行的 id 和 title 两个字段了。
删除命令语法和SELECT语句类似
1
|
>DELETE FROM pages WHERE id = 1;
|
MySQL中删除护具还不能恢复的,请谨慎操作
UPDATE命令
1
|
>UPDATE pages SET title="A new title", content="Some new content" WHERE id=2;
|
处理Unicode字符串
1
2
3
4
5
6
|
ALTER DATABASE scraping CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
ALTER TABLE pages CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE pages CHANGE title title VARCHAR(200) CHARACTER SET utf8mb4 COLLATE
utf8mb4_unicode_ci;
ALTER TABLE pages CHANGE content content VARCHAR(10000) CHARACTER SET utf8mb4 CO
LLATE utf8mb4_unicode_ci;
|
这四行语句改变的内容有:数据库、数据表,以及两个字段的默认编码都从 utf8mb4(严格说来也属于 Unicode,但是对大多数 Unicode 字符的支持都非常不好)转变成了 utf8mb4_unicode_ci。
存储爬取维基百科的信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import datetime
import random
import pymysql
conn = pymysql.connect(host='127.0.0.1', unix_socket='/tmp/mysql.sock',
user='root', passwd=None, db='mysql', charset='utf8')
cur = conn.cursor()
cur.execute("USE scraping")
random.seed(datetime.datetime.now())
def store(title, content):
cur.execute("INSERT INTO pages (title, content) VALUES (\"%s\",
\"%s\")", (title, content))
cur.connection.commit()
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
title = bsObj.find("h1").get_text()
content = bsObj.find("div", {"id":"mw-content-text"}).find("p").get_text()
store(title, content)
return bsObj.find("div", {"id":"bodyContent"}).findAll("a",
href=re.compile("^(/wiki/)((?!:).)*$"))
links = getLinks("/wiki/Kevin_Bacon")
try:
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs["href"]
print(newArticle)
links = getLinks(newArticle)
finally:
cur.close()
conn.close()
|
最后要注意的是,finally 语句是在程序主循环的外面,代码的最底下。这样做可以保证,无论程序执行过程中如何发生中断或抛出异常(当然,因为网络很复杂,你得随时准备遭遇异常),光标和连接都会在程序结束前立即关闭。无论你是在采集网络,还是处理一个打开连接的数据库,用 try...finally 都是一个好主意。
第六章、 读取文档
6.1 读取CSV文件
Python 的 csv 库主要是面向本地文件,就是说你的 CSV 文件得存储在你的电脑上。而进行网络数据采集的时候,很多文件都是在线的。不过有一些方法可以解决这个问题:
-
手动把 CSV 文件下载到本机,然后用 Python 定位文件位置;
-
写 Python 程序下载文件,读取之后再把源文件删除;
-
从网上直接把文件读成一个字符串,然后转换成一个 StringIO 对象,使它具有文件的属性。
虽然前两个方法也可以用,但是既然你可以轻易地把 CSV 文件保存在内存里,就不要再下载到本地占硬盘空间了。直接把文件读成字符串,然后封装成 StringIO 对象,让 Python 把它当作文件来处理,就不需要先保存成文件了。下面的程序就是从网上获取一个 CSV 文件(这里用的是 http://pythonscraping.com/files/MontyPythonAlbums.csv 里的 Monty Python 乐团的专辑列表),然后把每一行都打印到命令行里:
1
2
3
4
5
6
7
8
9
|
from urllib.request import urlopen
from io import StringIO
import csv
data = urlopen("http://pythonscraping.com/files/MontyPythonAlbums.csv")
.read().decode('ascii', 'ignore')
dataFile = StringIO(data)
csvReader = csv.reader(dataFile)
for row in csvReader:
print(row)
|
显示结果很长,开始部分是这样:
1
2
3
4
5
|
['Name', 'Year']
["Monty Python's Flying Circus", '1970']
['Another Monty Python Record', '1971']
["Monty Python's Previous Record", '1972']
...
|
从代码中你会发现 csv.reader 返回的 csvReader 对象是可迭代的,而且由 Python 的列表对象构成。因此,csvReader 对象可以用下面的方式接入:
1
2
|
for row in csvReader:
print("The album \""+row[0]+"\" was released in "+str(row[1]))
|
结果是
1
2
3
4
5
|
The album "Name" was released in Year
The album "Monty Python's Flying Circus" was released in 1970
The album "Another Monty Python Record" was released in 1971
The album "Monty Python's Previous Record" was released in 1972
...
|
另一种处理方法
1
2
3
4
5
6
7
8
9
10
|
from urllib.request import urlopen
from io import StringIO
import csv
data = urlopen("http://pythonscraping.com/files/MontyPythonAlbums.csv")
.read().decode('ascii', 'ignore')
dataFile = StringIO(data)
dictReader = csv.DictReader(dataFile)
print(dictReader.fieldnames)
for row in dictReader:
print(row)
|
csv.DictReader 会返回把 CSV 文件每一行转换成 Python 的字典对象返回,而不是列表对象,并把字段列表保存在变量 dictReader.fieldnames 里,字段列表同时作为字典对象的键:
1
2
3
4
|
['Name', 'Year']
{'Name': "Monty Python's Flying Circus", 'Year': '1970'}
{'Name': 'Another Monty Python Record', 'Year': '1971'}
{'Name': "Monty Python's Previous Record", 'Year': '1972'}
|
第七章 数据清洗
由于错误的标点符号、大小写字母不一致、断行和拼写错误等问题,零乱的数据(dirty data)是网络中的大问题。本章将介绍一些工具和技术,通过改变代码的编写方式,帮你从源头控制数据零乱的问题,并且对已经进入数据库的数据进行清洗。
7.1 编写代码清洗数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from urllib.request import urlopen
from bs4 import BeautifulSoup
def ngrams(input, n):
input = input.split(' ')
output = []
# 防止越界
for i in range(len(input)-n+1):
# 当n=2时,每两个字符串添加到一个列表中
output.append(input[i:i+n])
return output
html = urlopen("http://en.wikipedia.org/wiki/Python_(programming_language)")
bsObj = BeautifulSoup(html)
content = bsObj.find("div", {"id":"mw-content-text"}).get_text()
ngrams = ngrams(content, 2)
print(ngrams)
print("2-grams count is: "+str(len(ngrams)))
|
结果如下:
1
|
['of', 'free'], ['free', 'and'], ['and', 'open-source'], ['open-source', 'software']
|
我们继续对之前的输出结果进行清理
1
2
3
4
5
6
7
8
9
10
11
12
|
def ngrams(input, n):
input = re.sub('\n+', " ", input)
input = re.sub(' +', " ", input)
input = bytes(content, "UTF-8")
input = input.decode("ascii", "ignore")
print(input)
input = input.split(' ')
output = []
# 防止越界
for i in range(len(input)-n+1):
output.append(input[i:i+n])
return output
|
里首先把内容中的换行符(或者多个换行符)替换成空格,然后把连续的多个空格替换成一个空格,确保所有单词之间只有一个空格。最后,把内容转换成 UTF-8 格式以消除转义字符。
但是依旧存在下面这些问题
1
|
['Pythoneers.[43][44]', 'Syntax'], ['7', '/'], ['/', '3'], ['3', '=='], ['==', ' 2']
|
因此,需要再增加一些规则来处理数据。我们还可以制定一些规则让数据变得更规范:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import string
def cleanInput(input):
input = re.sub('\n+', " ", input)
input = re.sub('\[[0-9]*\]', "", input)
input = re.sub(' +', " ", input)
input = bytes(input, "UTF-8")
input = input.decode("ascii", "ignore")
cleanInput = []
input = input.split(' ')
for item in input:
item = item.strip(string.punctuation)
if len(item) > 1 or (item.lower() == 'a' or item.lower() == 'i'):
cleanInput.append(item)
return cleanInput
def ngrams(input, n):
input = cleanInput(input)
output = []
for i in range(len(input)-n+1):
output.append(input[i:i+n])
return output
|
但是还存在标签符号,我们用 import string 和 string.punctuation 来获取 Python 所有的标点符号。你可以在 Python 命令行看看标点符号有哪些:
1
2
3
|
>>> import string
>>> print(string.punctuation)
!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
|
这样得到的结果就很清晰了,但是依然存在重复的2-gram 序列
程序把每个 2-gram 序列都加入了列表,没有统计过序列的频率。掌握 2-gram 序列的频率,而不只是知道某个序列是否存在,这不仅很有意思,而且有助于对比不同的数据清洗和数据标准化算法的效果。如果数据标准化成功了,那么唯一的 n-gram 序列数量就会减少,而 n-gram 序列的总数(任何一个 n-gram 序列和与之重复的序列被看成一个 n-gram 序列)不变。也就是说,同样数量的 n-gram 序列,经过去重之后“容量”(bucket)会减少。
不过 Python 的字典是无序的,不能像数组一样直接对 n-gram 序列频率进行排序。字典内部元素的位置不是固定的,排序之后再次使用时还是会变化,除非你把排序过的字典里的值复制到其他类型中进行排序。在 Python 的 collections 库里面有一个 OrderedDict 可以解决这个问题:
1
2
3
4
5
|
rom collections import OrderedDict
...
ngrams = ngrams(content, 2)
ngrams = OrderedDict(sorted(ngrams.items(), key=lambda t: t[1], reverse=True))
print(ngrams)
|
这样还不够,大小写会被程序当成不同的序列,也存在重复
增加一行
1
2
|
input = input.upper()
# 全部转成大写
|
测试
单元测试
什么是单元测试
虽然不同公司的单元测试定义和实践方法大相径庭,但是一个单元测试通常包含以下特点。
- 每个单元测试用于测试一个零件(component)功能的一个方面。例如,如果从银行账户取出一笔金额为负数的美元,那么单元测试就要对负数抛出适当的错误信息。
通常,一个零件的所有单元测试都集成在同一个类(class)里。你可能有一个测试是针对从银行账户取出一笔金额为负数的美元,另一个测试是针对透支银行账户行为的单元测试。
-
每个单元测试都可以完全独立地运行,一个单元测试需要的所有启动(setup)和卸载(teardown)都必须通过这个单元测试本身去处理。单元测试不能对其他测试造成干扰,而且不论按何种顺序排列,它们都必须能够正常地运行。
-
每个单元测试通常至少包含一个断言(assertion)。例如,一个单元测试可以判断 2+2 的和是 4。有时,一个单元测试也许只包含一个失败状态(failure state)。例如,有这样一个单元测试,如果一个异常没有被抛出,测试失败;如果每个异常都顺利抛出,测试通过。
-
单元测试与生产代码是分离的。虽然它们需要导入然后在待测试的代码中使用,但是它们一般被保留在独立的类和目录中。
python单元测试
Python 的单元测试模块 unittest,所有标准版 Python 安装后都有。只要先导入模块然后继承 unittest.TestCase 类,就可以实现下面的功能:
一个简单的示例
1
2
3
4
5
6
7
8
9
10
11
|
import unittest
class TestAddition(unittest.TestCase):
def setUp(self):
print("Setting up the test")
def tearDown(self):
print("Tearing down the test")
def test_twoPlusTwo(self):
total = 2+2
self.assertEqual(4, total)
if __name__ == '__main__':
unittest.main()
|